

- Biblioteca de Mídia - Como carregar imagens e arquivos
- Número de Perguntas por Pesquisa
- Criando uma pesquisa a partir de um documento do Word
- Como excluir, adicionar e editar perguntas e respostas de uma pesquisa ao vivo
- Blocos de pesquisa
- Randomização de Blocos
- Randomização de Perguntas
- Biblioteca de Escalas
- O que é teste monádico?
- O que são testes monádicos sequenciais?
- Suporte de extração para Tipos de Pergunta de seletor de Imagem
- O que são testes de comparação?
- Mensagens de Validação Personalizadas
- Construindo pesquisas com o QxBot
- Extraktionsunterstützung para Fragetypen mit Bildauswahl
- Opções de visualização da pesquisa
- Edição e Colaboração em Pesquisas 2025 - FAQ
- Testing Send
- Add Questions From a Document
- Tipos de perguntas básicas
- Tipos de perguntas avançadas
- Tipos de pergunta de múltipla escolha
- Pergunta de texto - Caixa de Comentários
- Matriz de escalas de múltiplos pontos
- Ranking
- Classificação com emoji
- Pergunta de imagem
- Data e Hora
- Pergunta reCAPTCHA
- Tipo de pergunta NPS - Net Promoter Score
- Tipo de Pergunta Van Westendorp - Sensibilidade ao Preço
- Estudo de Análise Conjunta Baseado em Escolha
- Matriz Lado a Lado
- Tipo de Pergunta Homúnculo
- Opções de resposta preditiva
- Questões de conteúdo estático
- Múltipla escolha: selecionar uma opção
- Múltipla escolha com seleção múltipla
- Pergunta de cronômetro de página
- Informações de contato (texto aberto)
- Pergunta de matriz com múltipla seleção
- Pergunta com matriz de planilha
- Pergunta de classificação de cartão fechada
- Matriz Flexível - Como fazer?
- Controle Deslizante de Texto
- Configuração de Tipos de Pergunta de Avaliação Gráfica
- Ordem de Classificação - Interface Arrastar e Soltar
- Matriz bipolar - controle deslizante
- Perguntas de matriz bipolar e likert
- Gabor Granger
- Assinatura Digital Verificada
- Tipo de Pergunta de Avaliação por Estrelas
- Pergunta de Divulgação nas Redes Sociais
- Pergunta de Anexar/Carregar Arquivo
- Constant Sum Question
- Informações de vídeo
- Conexão de plataforma
- Recrutamento de Comunidades
- Pergunta de classificação: vídeo TubePulse ™
- Classificação de cartão aberto
- Mapas - Tipo de Pergunta
- Live Cast
- Tipo de resposta e layout
- Reordenar Perguntas
- Question tips
- Exibição de caixa de texto
- Configurações de texto aberto
- Adicionando a opção 'Outro'
- Configurações de matriz
- Configurações de avaliação de imagem
- Opções de escala
- Configurações de Soma Constante
- Definindo respostas padrão
- Validação de opção exclusiva para perguntas de múltipla escolha
- Como fazer uma pergunta obrigatória
- Configurações de validação
- Remover mensagem de validação
- Separadores de perguntas
- Códigos de pergunta
- Quebra de página
- Texto de Introdução com Caixa de Seleção de Aceitação
- Validação RegEx
- Biblioteca de Perguntas
- Como incorporar um vídeo com a QuestionPro
- Posição inicial do controle deslizante
- Alternância na Exibição das Respostas
- Matriz - Foco Automático
- Validações de texto
- Configurações de entrada numérica - planilha
- Grupos de resposta [versão BETA]
- Perguntas Ocultas
- Formato de moeda do separador decimal
- Permitir vários arquivos - tipo de pergunta anexar/carregar
- Entrada de caixa de texto - Tipo de teclado
- Mergulho profundo
- Ordem de exibição das respostas
- Configurando exibição de cores alternadas
- Análise Conjunta - FAQ sobre Melhores Práticas de Implementação
- Limites para arquivos de imagem/multimídia
- Conceitos Proibidos em Conjoint
- Adicionar logotipo à sua pesquisa
- Customização de temas
- Configurações de exibição da pesquisa
- Avanço automático
- Barra de Progresso
- Opções de numeração automática de perguntas
- Barra de ferramentas de rede social
- Título do Navegador
- Imprimir ou baixar pesquisa como DOC do Word ou PDF
- Botões de navegação de pesquisa
- Tema Acessível - conformidade com 508
- Habilitar ou desabilitar botão de voltar e link de saída
- Layout de Foco
- Layout da pesquisa
- Layout da pesquisa - modo visual
- Integração Telly
- Integração com televisão
- URL do espaço de trabalho
- Layout Clássico
- Ramificação ou lógica de pulo
- Lógica de Ramificação Composta
- Ramificação composta
- Controle de Cota Baseado em Resposta
- Texto dinâmico/comentários
- Lógica de extração
- Mostrar/ocultar perguntas
- Lógica dinâmica de exibição/ocultação
- Lógica de pontuação
- NPS - Net promoter score
- Envio de texto por "Piping"
- Pesquisa em cadeia
- Looping
- Ramificação para encerrar pesquisa
- Segmentação de múltiplos critérios, agrupamento e operadores lógicos de ramificação disponíveis usando o Survey Analytics
- Lógica N de M selecionada
- Referência Lógica da Sintaxe com JavaScript
- Fluxo em bloco
- Looping de Blocos
- Referência de sintaxe do motor de pontuação
- Lógica de Sempre Extrair e Nunca Extrair
- Extração de Matriz
- Extração Bloqueada
- Atualização dinâmica de variável personalizada
- Randomização Avançada
- Exemplos de scripts personalizados
- Script Personalizado
- Survey Logic Builder - AI
- Configurações da pesquisa
- Salvar e Continuar Depois
- Desabilitar respostas múltiplas
- Fechar ou desativar pesquisa
- Notificações e alertas por e-mail para respostas completas
- Notificações com base em Critérios de Resposta
- Tempo limite da pesquisa / Tempo limite da sessão
- Opções de Finalização de Pesquisas | QuestionPro
- Relatório Spotlight
- Imprimir respostas da pesquisa
- Pesquisar e substituir
- Cronômetro de Pesquisa
- Permite múltiplos entrevistados da mesma máquina?
- Configurações de Tamanho de Entrada de Texto
- Notificações - E-mail de Confirmação do Administrador
- Data e hora de fechamento da pesquisa
- Dados de Localização do Respondente
- Modo de revisão
- Revise, edite e imprima respostas
- Geocodificação
- Barra de Progresso Clássica
- Response Quota
- Verificação de idade
- Opções de pesquisa | Ferramentas
- Copiando uma pesquisa existente
- Edição de pesquisas compartilhadas
- Compartilhamento de Pesquisa
- Pastas - Organizar Pesquisas
- Procurando por uma pesquisa em minha conta
- Compartilhamento de lista de e-mail
- Logs de Auditoria do Sistema
- Compartilhar Pesquisas Individuais
- Compartilhamento e Colaboração em Pesquisas
- Versões da Pesquisa
- Elabore e publique pesquisas
- Segurança da Pesquisa - Autenticação
- Pesquisa global com proteção por senha
- Autenticação usando apenas convites por e-mail
- E-mail de pesquisa e proteção por senha
- Como definir segurança por senha em uma pesquisa para respondentes com identificadores únicos
- Autenticação de nome de usuário e senha
- Segurança SSL
- Configurando autenticação do Facebook para uma pesquisa
- Autenticação usando login único
- URLs de mídia criptografados
- Link da Pesquisa
- URLs de Pesquisa Personalizadas
- Criando convite da pesquisa por email
- Fusão de correio e personalização de e-mails
- Configurações de convites por e-mail
- Filtro de lista de e-mails
- Enviando lembretes de pesquisa
- Lote de exportação para distribuição externa
- Status atual do e-mail
- Índice de spam
- Pesquisas por SMS
- Pesquisas por telefone e papel
- Adicionando respostas manualmente
- Preços de SMS
- Incorporar Pergunta no E-mail
- Excluindo listas de e-mail
- Distribuição de Pesquisa Multilíngue
- SMTP
- Configurar o endereço de e-mail de resposta para os convites de pesquisa enviados via QuestionPro
- Autenticação de domínio
- Solução de problemas de entrega de e-mail
- Códigos QR
- Email Delivery and Deliverability
- App offline - Temas
- Loop de pesquisa
- Usando o aplicativo móvel QuestionPro
- Modo Quiosque
- Sincronizar os dados do aplicativo
- Revise a resposta / imprima o pdf no aplicativo offline
- Auditoria de campo e dispositivo
- Variáveis de Dispositivo Offline
- Sincronizar respostas manualmente
- Hardware do dispositivo
- Detecção facial no modo quiosque
- Texto para fala
- Notificação Push
- Aplicativo Offline | Melhores práticas
- Dashboard da pesquisa
- Overall participant statistics
- Análise de desistências
- Banner tables
- Análise TURF
- Criar Análise de Tendências
- Análise de correlação
- Relatório de comparação
- O que é a análise de GAP/Lacunas?
- Personalizar Cálculo Estatístico
- O que é média ponderada?
- Análise de Gráfico Spider
- Análise de Cluster
- Filtros do painel
- Dashboard - Opções de download
- Teste de Imagem HotSpot
- Heatmap Analysis
- Ordem de classificação ponderada
- Opções de resposta de agrupamento de tabulação cruzada
- Teste A/B em pesquisas QuestionPro
- Qualidade de dados
- A qualidade dos dados termina
- Gráfico de mapa de calor para perguntas do tipo matriz
- Teste de Proporções de Coluna
- Identificador de resposta
- Análise de alcance TURF
- Edição em Massa de Respostas
- Ponderação e balanceamento
- Designs de Análise Conjunta
- Cálculo dos valores de utilidade na análise de escolha discreta do Conjoint
- Análise Conjunta - Cálculos / Metodologia
- Análise Conjunta – Importância do Atributo
- Análise Conjunta – Perfis
- Simulador de Segmentação de Mercado
- Análise Conjunta – Valor da Marca
- Escalonamento de Diferença Máxima | Max-Diff
- Configurações da Maxdiff
- Análise MaxDiff Ancorada
- Escala Max Diff - Perguntas Frequentes
- MaxDiff - Interpretando Resultados
- Envio de Relatórios por E-mail Automático
- Qualidade de dados - respostas padronizadas
- Qualidade dos Dados - Palavras Sem Sentido
- Importar Dados Externos para Nova Pesquisa
- Histórico de download
- Consolidar Relatório | Combinar Relatórios
- Excluir Pesquisa e Dados
- Qualidade dos dados - Todas as caixas de seleção marcadas
- Exportando dados para Word ou PowerPoint
- Agendador de Relatórios
- Datapad para uma pesquisa
- Grupo de Notificação
- Representação de Caixa de Seleção Não Selecionada
- Mesclar dados 2.0
- Detecção de Plágio
- Dados de localização baseados em IP
- Exportar Dados - Download de Arquivo SPSS
- Nome da variável SPSS
- Atualizando Perfil de Usuário
- Como atualizar o fuso horário
- Unidades de Negócio/Equipes
- Adicionar Usuários
- Painel de Uso
- Licença de Usuário Único
- Restrições de Licença
- Solução de problemas de login
- Pacote de Suporte de Software
- E-mail de Boas-Vindas
- Funções e permissões do usuário
- Adicionar usuários em massa
- Verificação de conta usando autenticação de dois fatores (verificação em 2 etapas)
- Acesso à rede
- Alterando a propriedade da pesquisa
- Não foi possível acessar o suporte por chat
- Navegando nos Produtos da QuestionPro
- Agency Partnership Referral Program
- Response Limits
- Conformidade com a CAN-SPAM
- Regulamento Geral de Proteção de Dados (GDPR)
- SOC 2 Segurança
- Garantia de Anonimato do Respondente (RAA)
- Segurança
- Conformidade com a Lei de Privacidade do Consumidor da Califórnia (CCPA)
- GDPR - Direito de ser Esquecido
- GDPR: solicitação de direitos de dados
- Declaração de acessibilidade do QuestionPro
- Centro de dados
- Strong Password
- Automated deletion of data

Análise Conjunta – Perfis
Perfis em um tipo de pergunta de Análise Conjunta são diferentes configurações que são apresentadas aos respondentes. Cada perfil é uma combinação de diferentes níveis de vários atributos (Por exemplo, Marca, Custo, Recursos). Ao avaliar esses perfis, os respondentes revelam suas preferências e trade-offs, permitindo que os pesquisadores estimem a importância relativa de cada atributo e seus níveis na influência da escolha do consumidor.
Com a QuestionPro, você pode acessar Perfis em um tipo de pergunta de Análise Conjunta como mostrado abaixo: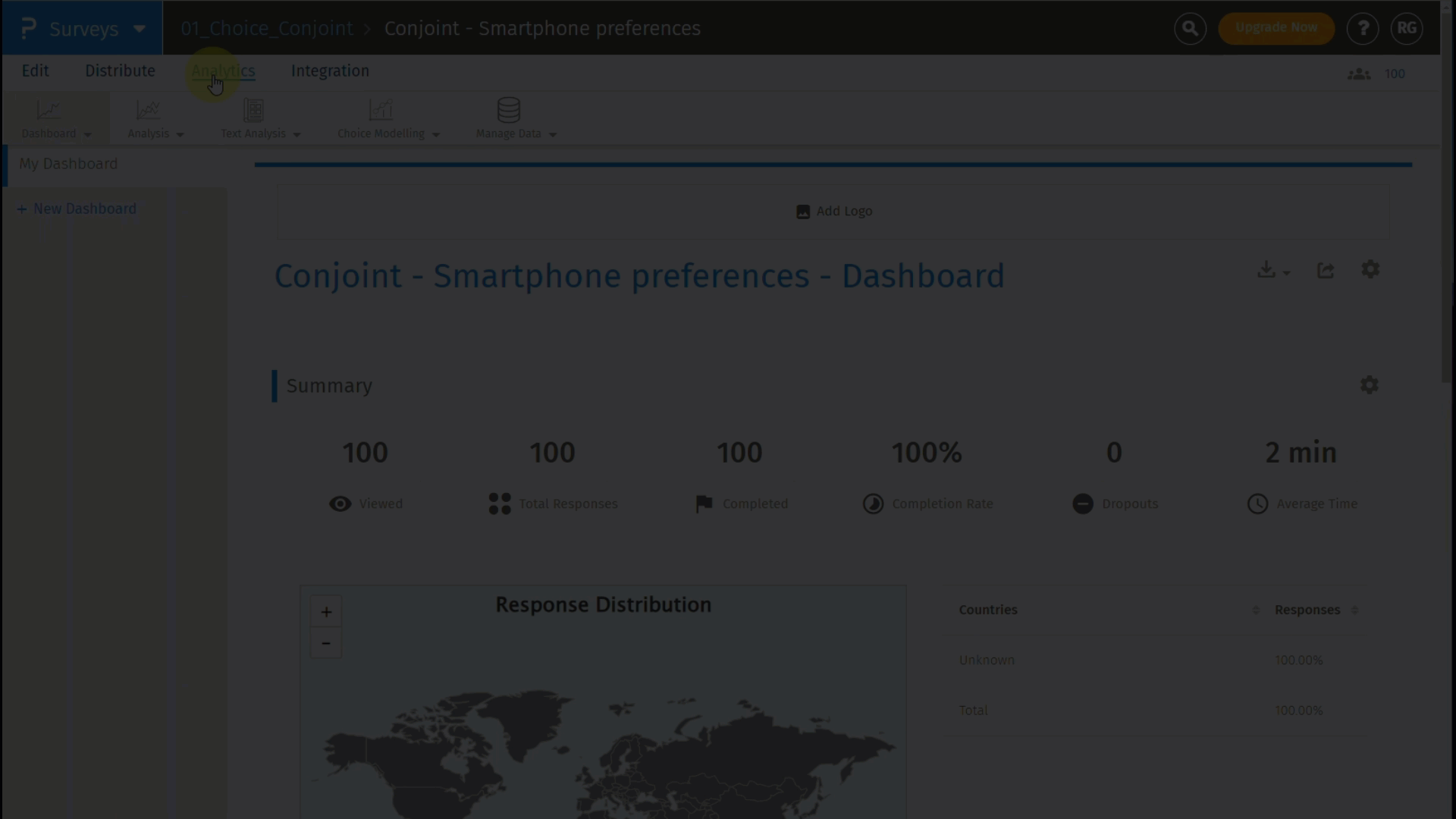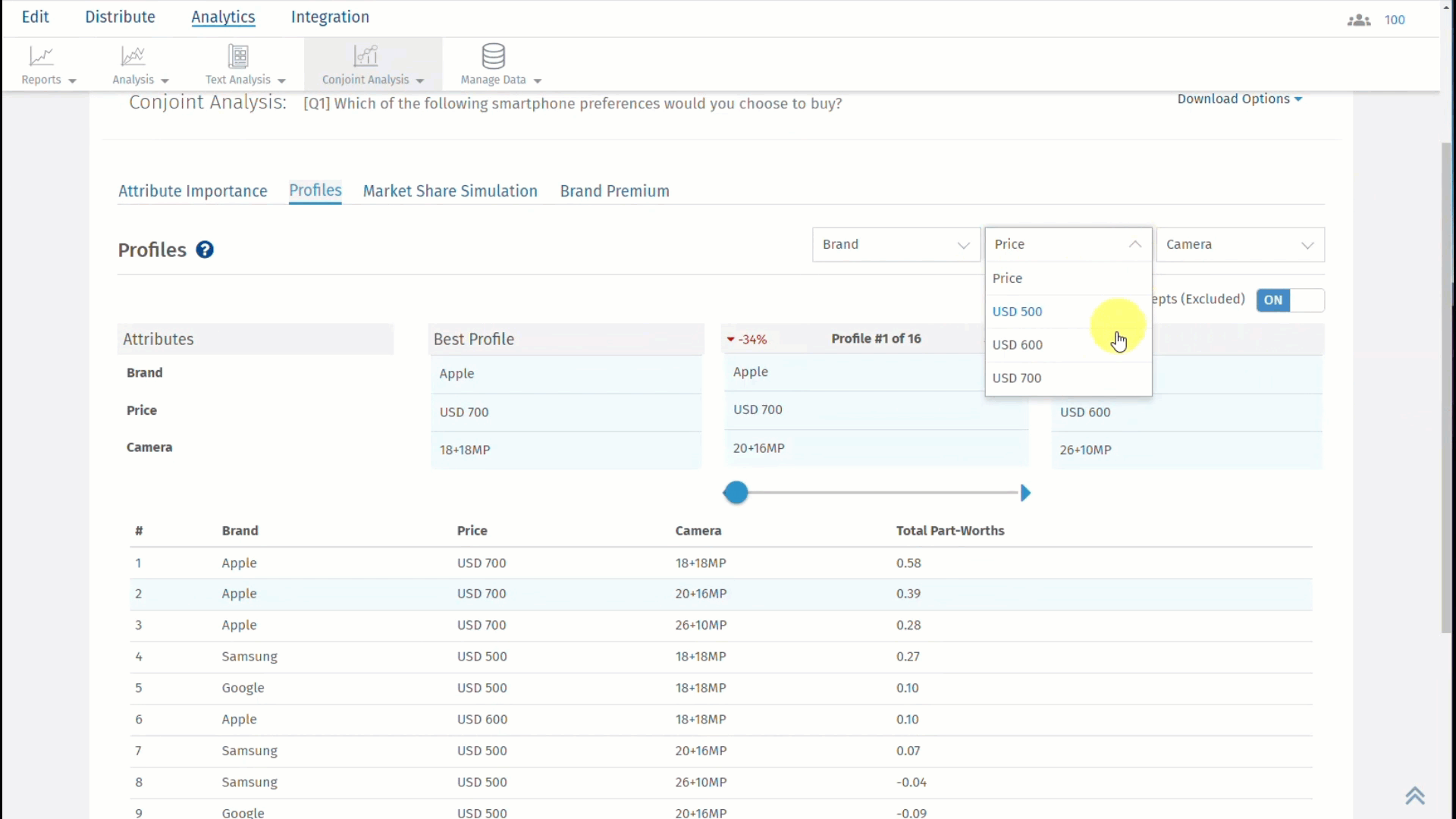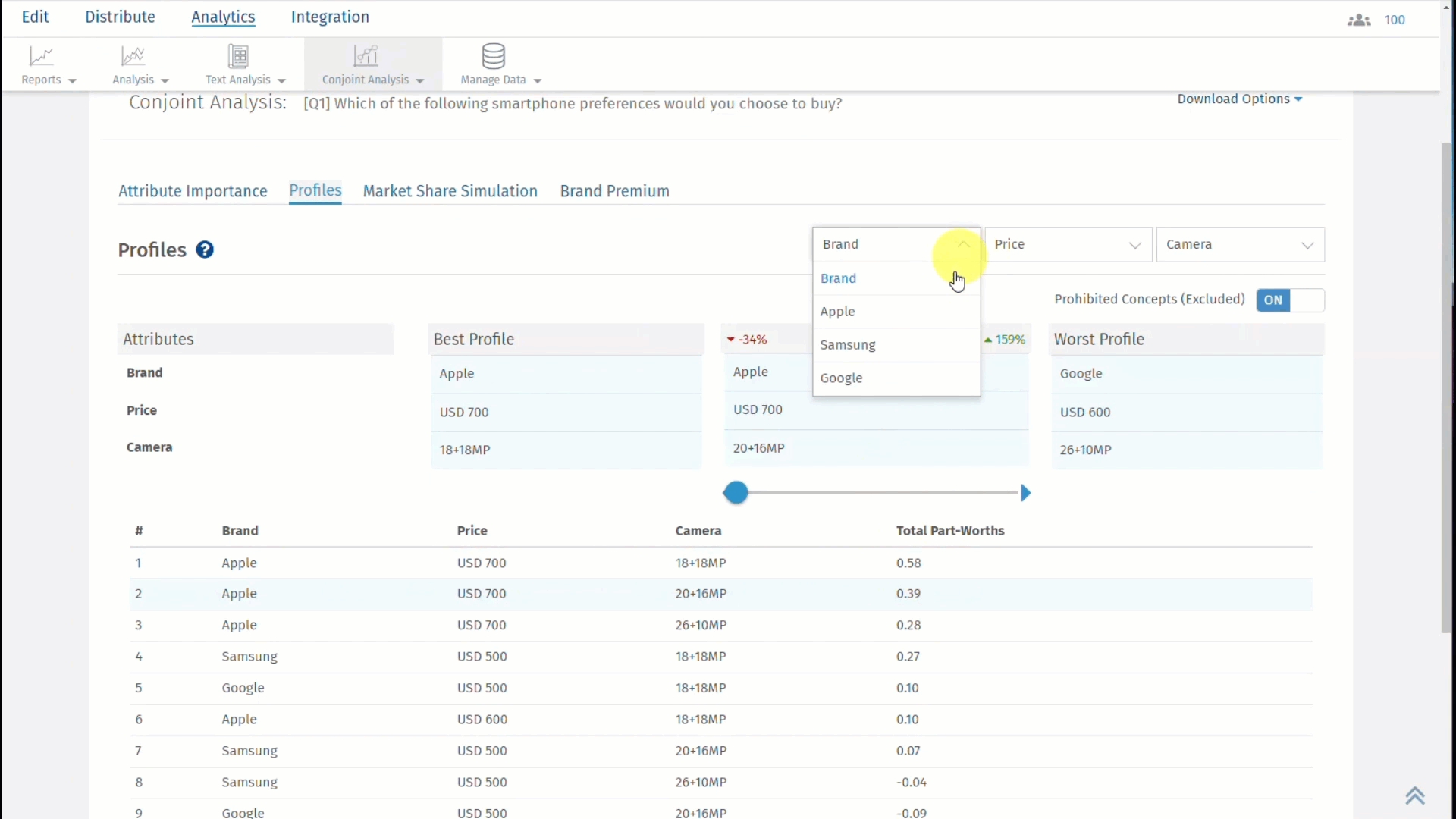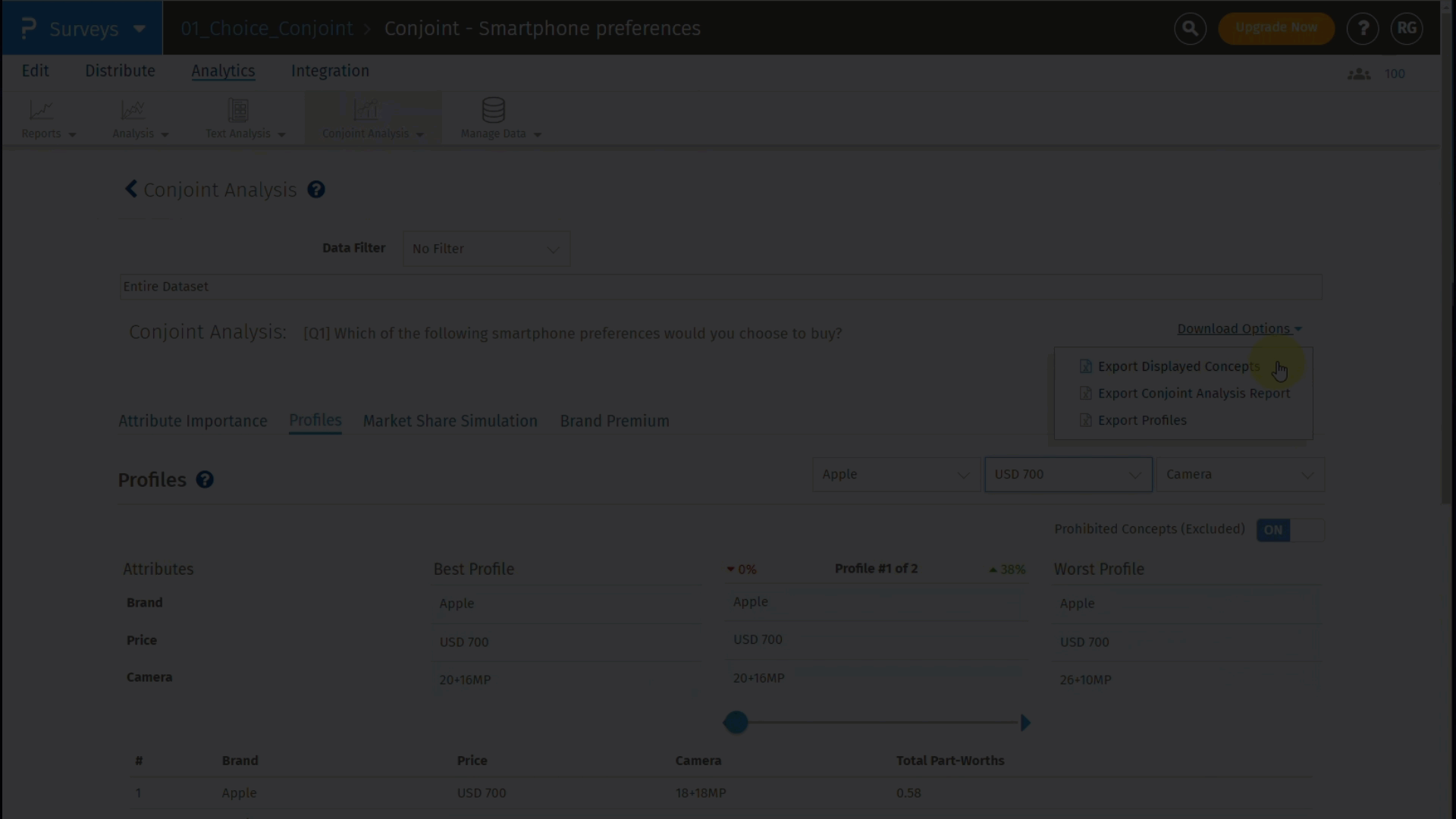
Clique em Análise
 Vá para:
Modelagem de Escolha » Análise Conjunta
Vá para:
Modelagem de Escolha » Análise Conjunta
 Selecione a pergunta para a qual a análise é necessária e clique em Próximo Passo
Selecione a pergunta para a qual a análise é necessária e clique em Próximo Passo
 Clique na segunda aba, que é Perfis e os resultados serão exibidos como mostrado abaixo:
Clique na segunda aba, que é Perfis e os resultados serão exibidos como mostrado abaixo:
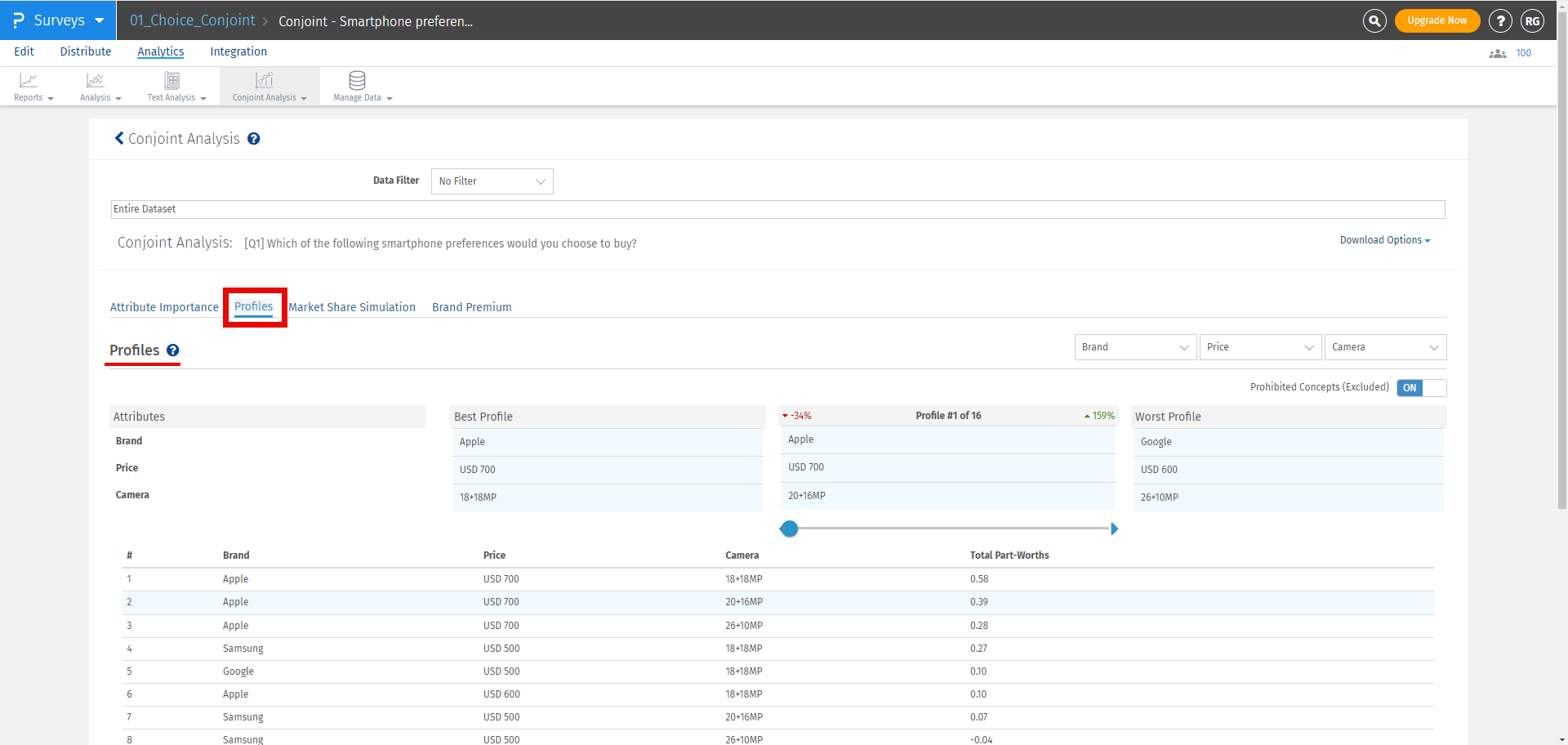 O melhor perfil é sempre exibido à esquerda e o pior perfil à direita. No meio, você pode selecionar um perfil personalizado para ver como ele se compara com o melhor e o pior perfil.
O melhor perfil é sempre exibido à esquerda e o pior perfil à direita. No meio, você pode selecionar um perfil personalizado para ver como ele se compara com o melhor e o pior perfil.
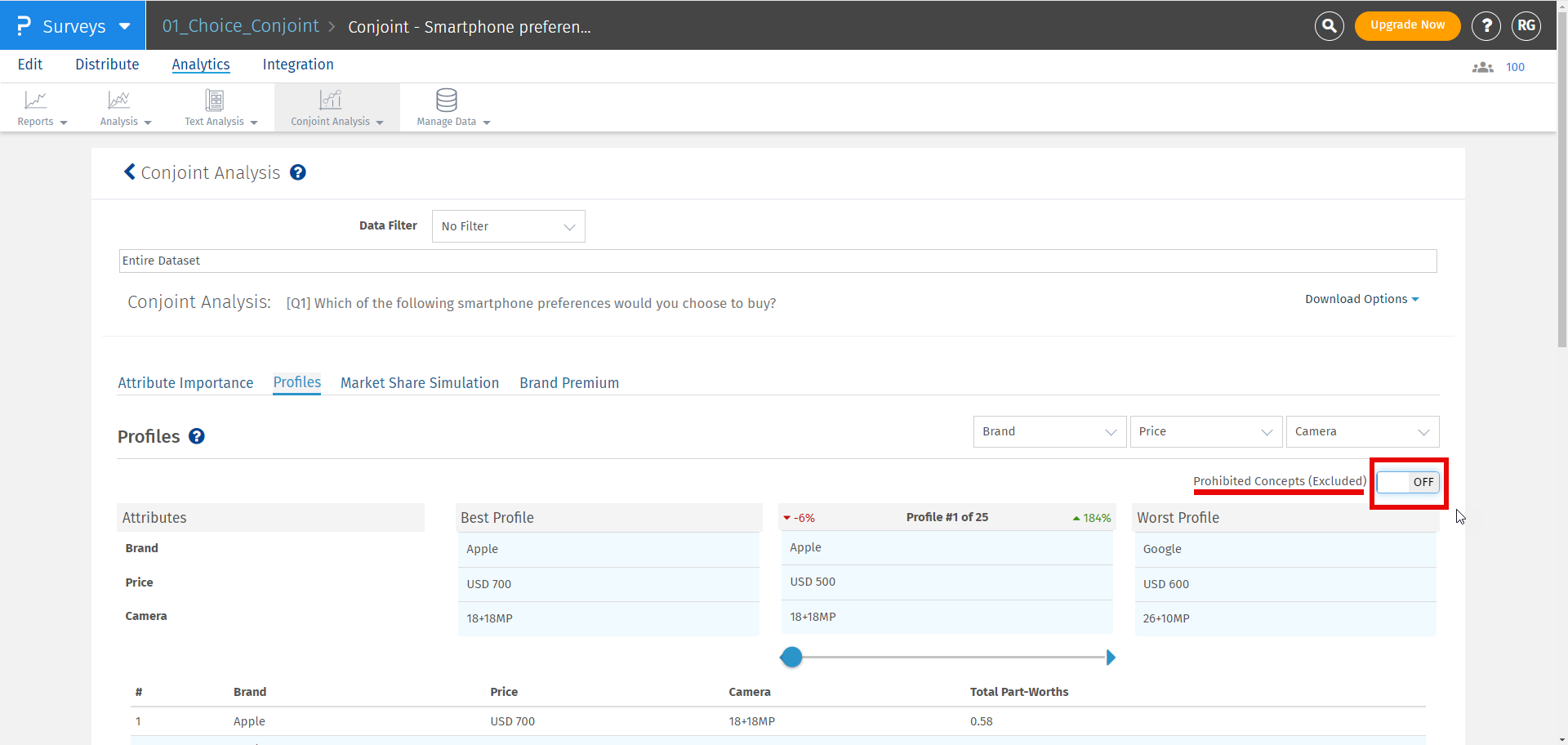
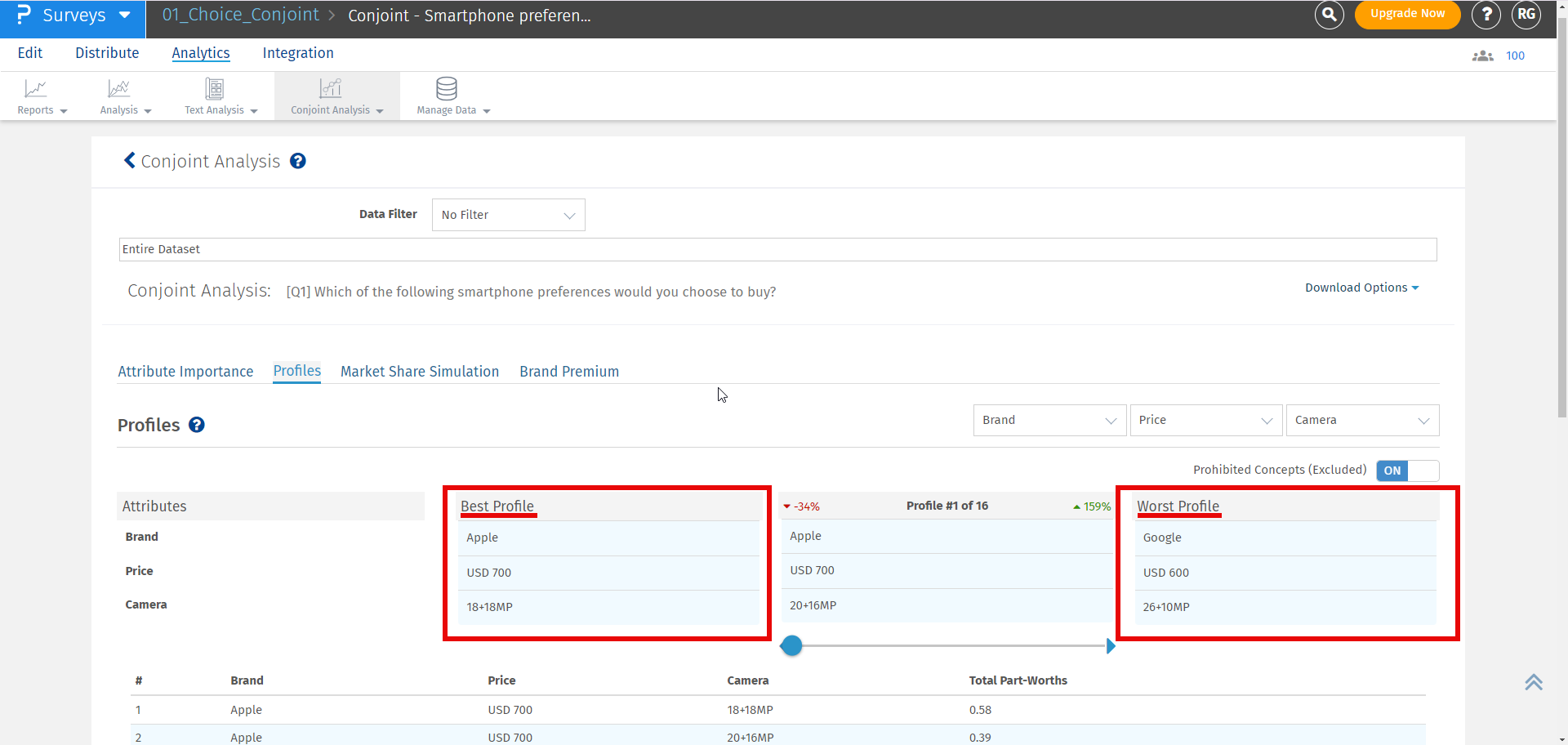 Se qualquer par for selecionado como par proibido, ele não será exibido no perfil melhor, pior ou personalizado. Se o usuário ainda quiser ver os pares proibidos, ele pode habilitar a opção de incluir pares proibidos.
Se qualquer par for selecionado como par proibido, ele não será exibido no perfil melhor, pior ou personalizado. Se o usuário ainda quiser ver os pares proibidos, ele pode habilitar a opção de incluir pares proibidos.
 Para o perfil selecionado, você pode ver a diferença em pontos percentuais entre o melhor perfil e o perfil selecionado em vermelho. Por outro lado, a diferença em pontos percentuais entre o pior perfil e o perfil selecionado é exibida em verde.
Para o perfil selecionado, você pode ver a diferença em pontos percentuais entre o melhor perfil e o perfil selecionado em vermelho. Por outro lado, a diferença em pontos percentuais entre o pior perfil e o perfil selecionado é exibida em verde.
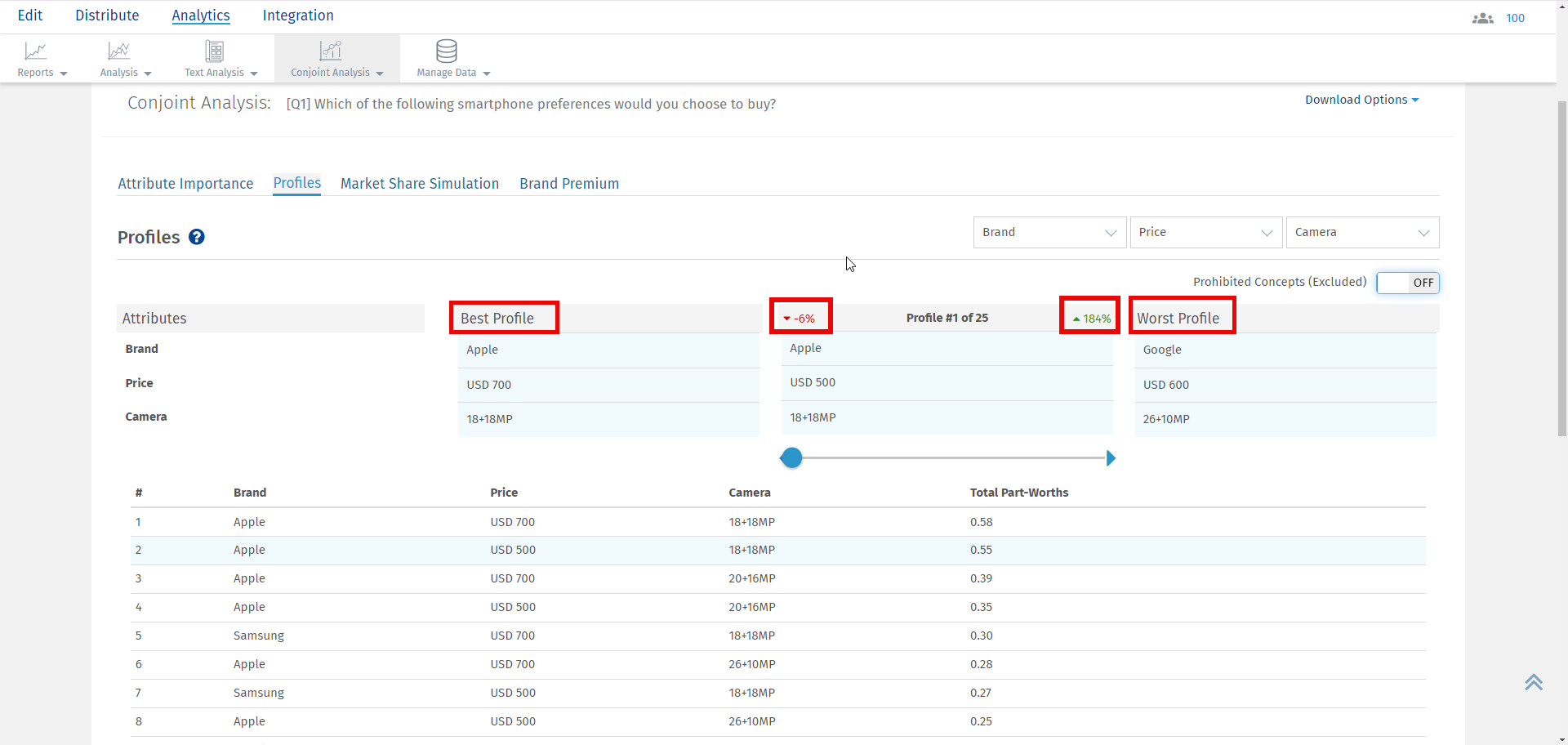 Nota: Atributo e nível com o maior Valor de Utilidade Parcial Total serão selecionados como o Melhor Perfil e aquele com o menor valor de Utilidade Parcial Total será selecionado como o Pior Perfil.
Nota: Atributo e nível com o maior Valor de Utilidade Parcial Total serão selecionados como o Melhor Perfil e aquele com o menor valor de Utilidade Parcial Total será selecionado como o Pior Perfil.
Usamos o seguinte algoritmo para calcular as Utilidades Parciais do Conjoint CBC:
Notação
Seja R o número de respondentes, com indivíduos r = 1 ... RSeja T o número de tarefas que cada respondente vê, com t = 1 ... T
Seja C o número de configurações (ou conceitos) que cada tarefa t tem, com c = 1 ... C (C em nosso caso é geralmente 3 ou 4)
Se temos A atributos, a = 1 a A, com cada atributo tendo La níveis, l = 1 a La, então a utilidade parcial para um atributo/nível específico é w’(a,l). É por esta (matriz irregular) de utilidades parciais que estamos resolvendo neste exercício.
Podemos simplificar isso para uma matriz unidimensional w(s), onde os elementos são:{w’(1,1), w’(1,2) ... w’(1,L1), w’(2,1) ... w’(A,LA)} com w tendo S elementos.
Uma configuração específica x pode ser representada como uma matriz unidimensional x(s), onde x(s)=1 se o nível/atributo específico estiver presente, e 0 caso contrário.
Seja Xrtc a configuração específica da c-ésima configuração na t-ésima tarefa para o r-ésimo respondente. Assim, o design do experimento é representado pela matriz de quatro dimensões X com tamanho RxTxCxS
Se o respondente r escolher a configuração c na tarefa t, então Yrtc=1; caso contrário, 0.
Utilidade de Uma Configuração Específica
A Utilidade Ux de uma configuração específica é a soma das utilidades parciais para os atributos/níveis presentes na configuração, ou seja, é o produto escalar x.wO Modelo Logit Multinomial
Para uma escolha simples entre duas configurações, com utilidades U1 e U2, o modelo MNL prevê que a configuração 1 será escolhidaEXP(U1)/(EXP(U1) + EXP(U2)) das vezes (um número entre 0 e 1).
Para uma escolha entre N configurações, a configuração 1 será escolhida
EXP(U1)/(EXP(U1) + EXP(U2) + ... + EXP(UN)) das vezes.
Probabilidade de Escolha Modelada
Seja a probabilidade de escolha (usando o modelo MNL) de escolher a c-ésima configuração na t-ésima tarefa para o r-ésimo respondente:Prtc=EXP(xrtc.w)/SUM(EXP(xrt1.w), EXP(xrt2.w), ... , EXP(xrtC.w))
Medida de Log-verossimilhança
A medida de Log-verossimilhança LL é calculada como:
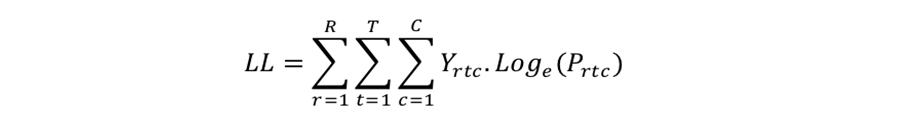
Prtc é uma função do vetor de utilidade parcial w, que é o conjunto de utilidades parciais que estamos resolvendo.
Resolvendo Para Utilidades Parciais Usando Máxima Verossimilhança
Resolvemos para o vetor de utilidade parcial encontrando o vetor w que dá o valor máximo para LL. Note que estamos resolvendo para S variáveis.Este é um problema de maximização contínua não linear multidimensional e requer uma biblioteca de solucionador padrão. Usamos o Algoritmo Simplex de Nelder-Mead.
A função de Log-verossimilhança deve ser implementada como uma função LL(w, Y, X) e, em seguida, otimizada para encontrar o vetor w que nos dá um máximo. As respostas Y e o design X são dados e constantes para uma otimização específica. Os valores iniciais para w podem ser definidos para a origem 0.
As utilidades parciais finais w são reescalonadas para que as utilidades parciais para qualquer atributo tenham uma média de zero, simplesmente subtraindo a média das utilidades parciais para todos os níveis de cada atributo.